想象一下,告诉您的计算机查找度假出租屋,比较五个站点,填写预订表格,并确认距离海滩最近的一个。你去煮咖啡吧。当你回来时就完成了。这就是“计算机使用代理”的承诺——人工智能可以像人类一样读取您的浏览器屏幕并单击、滚动和键入,无需特殊插件。
OpenAI 首先通过 Operator 进行了尝试,于 2025 年 1 月推出,每月 200 美元,然后并入 ChatGPT Agent 并于 8 月关闭。 Google 有 Gemini 2.5 计算机使用。两者都是专有的、基于云的且运行成本昂贵。
本周,微软研究院发布了一个名为 Fara1.5 的微型模型,在重要的基准测试中,它击败了这两个模型。
该系列有三种规模:40 亿、90 亿和 270 亿个参数,全部基于 Qwen3.5 构建,Qwen3.5 是微软针对浏览器工作进行微调的阿里巴巴基础模型,所有权重均公开发布。 (参数决定了人工智能模型的知识广度,更一般地意味着更高的能力。)
要实现这一目标,需要从头开始重新思考整个开发过程。 “我们从一个简单的问题开始:怎样才能让一个小模型真正擅长代理任务?” AI Frontiers 团队写道。 “答案涵盖了整个生命周期——数据生成、训练目标、模型设计和编排必须一起重新设计,而不是孤立的。”
基准
Online-Mind2Web 是 Microsoft 想要出色完成任务的重要基准。它测试人工智能代理在 136 个流行的实时网站上正确完成 300 项不同的现实世界任务的频率(例如比较产品、填写表格和预订服务),并以在实际不断变化的互联网上正确完成任务的百分比进行评分。
Fara1.5-27B 得分 72%。 OpenAI 运营商得分为 58.3%。 Google 的 Gemini 2.5 计算机使用得分为 57.3%。 Yutori 的 Navigator n1(顶级专有替代品)达到了 64.7%。即使是中型模型 Fara1.5-9B,也达到了 63.4%,领先于 OpenAI 和 Google。
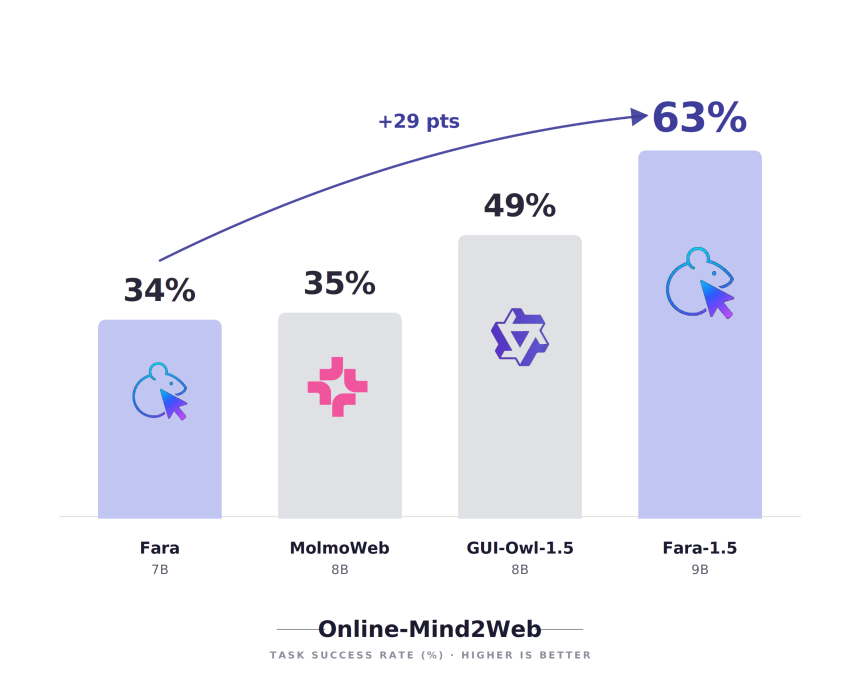
开源竞争对手也表现不佳。阿里巴巴的 GUI-Owl-1.5 在 80 亿个参数下得分为 48.6%。 AI2 的 MolmoWeb 得分为 35.3%。微软自己的上一个型号 Fara-7B 得分为 34.1%,这使得该版本在同等大小的情况下几乎是前代型号的两倍。
在 WebVoyager 上,测量实时网络上任务成功的第二个基准测试的得分相同,Fara1.5-27B 达到 88.6%,超过 OpenAI Operator 的 87.0%,并以 83.0% 的成绩击败 H 公司的 300 亿参数 Holo2。
它是如何学习的
秘密武器是训练管道。微软使用名为 FaraGen1.5 的系统来生成训练数据。聪明的地方在于:他们使用 GPT-5.4(OpenAI 的模型)作为“教师代理”来演示如何完成浏览器任务。这些演示成为 Fara1.5 的训练数据。您实际上是在使用 OpenAI 最强大的模型来训练竞争对手的开源模型。
他们还创建了六个虚假的、功能齐全的真实网站复制品(电子邮件客户端、日历、市场),因此该模型可以练习需要登录或不可逆转操作(例如实际发送电子邮件或预订航班)的任务,而无需接触真实帐户。这就是所谓的合成领域训练,这也是 Fara1.5 比其前身更好地处理“门控”任务的重要原因。
每个模型都被设计为在做一些无法撤销的事情之前停下来询问。微软研究院高级产品经理 Yash Lara 告诉 VentureBeat,“平衡关键点等强有力的保障措施与无缝用户旅程是关键。” “拥有像 Microsoft Research 的 Magentic-UI 这样的 UI,对于为用户提供必要时进行干预的机会至关重要,同时还有助于避免审批疲劳。”
这很重要,因为 OpenAI 在推出 ChatGPT Agent 时并没有意识到其中的风险。该公司写道:“当您将 ChatGPT 代理登录到网站或启用连接器时,它将能够访问这些来源的敏感数据,例如电子邮件、文件或帐户信息。”
Fara1.5 通过 MagenticLite 运行所有内容,这是一个沙盒浏览器环境,可记录每个操作并允许用户随时停止代理。
浏览器人工智能已成为一场拥挤的竞赛——Chrome 中的 Google 的 Gemini、Perplexity 的 Comet、Chrome 中的 Anthropic 的 Claude。 Fara1.5 的优势在于它是开放的:公开权重,GitHub 上开放推理代码,在您控制的硬件上运行。 Fara1.5-9B 现已在 Azure AI Foundry 上上线; 4B 和 27B 型号即将上市。微软表示,计划下一步将 Fara1.5 扩展到浏览器之外,扩展到桌面和企业软件。